
Mapping the real supply chain of AI
Why simple regulatory categories of providers and deployers are not the best way to think about practical risk management in the AI supply chain.

Doing AI Governance is a newsletter by AI Career Pro about the real work of making AI safe, secure and lawful.
Please subscribe (for FREE) to our newsletter so we can keep you informed of new articles, resources and training available. Plus, you’ll join a global community of more than 3,800 AI Governance Pros learning and doing this work for real. Unsubscribe at any time.
It was an ordinary morning in Cardiff’s city centre, the largest city in South Wales. But if you’ve ever been there, you know - it’s not really a city, more a large and pretty Victorian town. Shoppers drifted past the arcades as a police van idled at the curb with a camera mast pointed at the crowd. On a monitor inside, live facial-recognition (LFR) software compared every passing face to a pre-built watchlist. If the system thought it saw a match, it flashed an alert.
One of those passers-by, a local named Ed Bridges, didn’t like it. He hadn’t done anything wrong. He hadn’t been told his face would be scanned, how the images would be used, or even who decided which faces belonged on the watchlist. Bridges’ problem was simple and human: he didn’t like the idea of being treated as a biometric suspect by default —without clear rules, limits, or the chance to meaningfully object.
So he took South Wales Police to court.
What followed is a tidy lesson in AI accountability, and an instructive example of how risk travels through a chain of suppliers that defy simple categories.
In August 2020, the UK Court of Appeal ruled the deployment unlawful.1 Not because facial recognition is off-limits, but because this rollout rested on assurances from the South Wales Police that didn’t reach back through the chain.
Where/when and who. The force couldn’t point to clear, specific rules for when the system would run or who could be placed on the watchlist. That’s not just a policy gap, it’s a data-origin problem: which images were sourced, under what authority, and how could someone challenge inclusion?
Privacy assessment. The DPIA read like a template while the system scanned everyone in view. That’s a process and infrastructure gap: what is actually captured, how long is it retained, who else (including vendors) can access it, and what happens after a false alert?
Bias checks. The force hadn’t taken reasonable steps to test for uneven performance across groups. That’s an upstream vendor issue as much as a deployer one: you need evidence about how the model was built, tuned, and tested, not just a brochure claim that it “works.”
In short, promises weren’t enough. To operate safely, the police needed operational controls and vendor evidence at multiple layers that matched how the system actually worked, from the images that seeded the watchlist, to the model’s thresholds and update cadence, to the real-world procedures for review, retention, and redress.
That’s why I think the Bridges case resonates beyond policing. On paper, the police were “responsible.” They had audit reports, vendor due diligence, privacy impact assessments, legal reviews, operating oversight. In practice, running live AI in public meant proving that every link in the chain—data sourcing, vendor design, deployment settings, and day-to-day handling—was necessary, proportionate, and fair.
The court didn’t ban LFR; it banned trust without traceability. If you’re going to put powerful AI on the street, you need auditable proof that your upstream suppliers, your internal processes, and your real-time operators are all doing the right thing.
But how do you do that for real?
Accountability within the Supply Chain
Who is accountable when an AI system fails? It’s a straightforward question, but one with an increasingly complex answer. And sometimes what’s written in law or regulatory requirements bear little resemblance to what you’ll experience in practice. Tracing accountability through the web of connections in an AI system, from where a risk emerges to where it’s consequences are felt, is difficult. Proving the integrity of claims in each of those links, that’s even harder.
Now the EU AI Act takes an understandable approach to allocating accountability: it defines providers (who place AI systems on the market) and deployers (the professional operators using systems under their authority), and it recognises affected persons whose lives are shaped by AI decisions, alongside some secondary actors like importers, distributors, notified bodies, and market-surveillance authorities. Clean categories, clear responsibilities, understandable in a regulatory model that has to assign specific accountabilities in some enforceable way. It generally comes down to: You’re a provider or you’re a deployer, or both.
But spend one day with an organisation building or using AI, and you see the limits of that neat idea. Accountability often spans multiple organisations, each controlling only a small slice of the whole system. The Act’s roles are a compliance scaffold, but they don’t describe how work actually gets done across data, models, infrastructure, platforms, apps, and users. And having almost no bearing on how risks emerge and pass through networks of suppliers, trying to think in terms of providers and deployers hasn’t much practical worth in real supply chain risk management.
ISO/IEC 42001 (the AI management-system standard) pushes a small step closer to operational reality. It expects organisations to define their stakeholder positions for each AI system, and uses a more granular five-role framing: customer, provider, producer, partner, and subject. That lens helps you document the different hats your organisation wears (who buys, who builds, who packages, who integrates, and who is affected). It’s better for scoping and assigning ownership than the statutory trio.
But it’s still a management-system abstraction. The labels are high-level; they don’t expose the messy dependencies, hand-offs, and update dynamics you inherit from upstream vendors and shared infrastructure. The practical reality is that the EU AI Act gives you a workable legal map; ISO 42001 adds helpful distinctions; neither tells you what’s actually on the ground. Neither are much use for real world supply chain risk in AI.
The Seven-Layer Reality
I’ve found it’s more useful to think of the AI supply chain as working through seven interconnected layers, where data flows from collection through annotation to model development, then via cloud infrastructure and software platforms to applications, finally reaching end users. This seemingly linear process masks a web of dependencies where companies often operate across multiple layers simultaneously. Risks emerge at each layer of the supply chain, and could escalate through multiple layers all the way from data sources at Layer 1 to usage at Layer 7. It’s much less about provider/deployer and more about depencies in both directions up and down the seven layers. And at each layer risks emerge, though their impact may be felt far away.
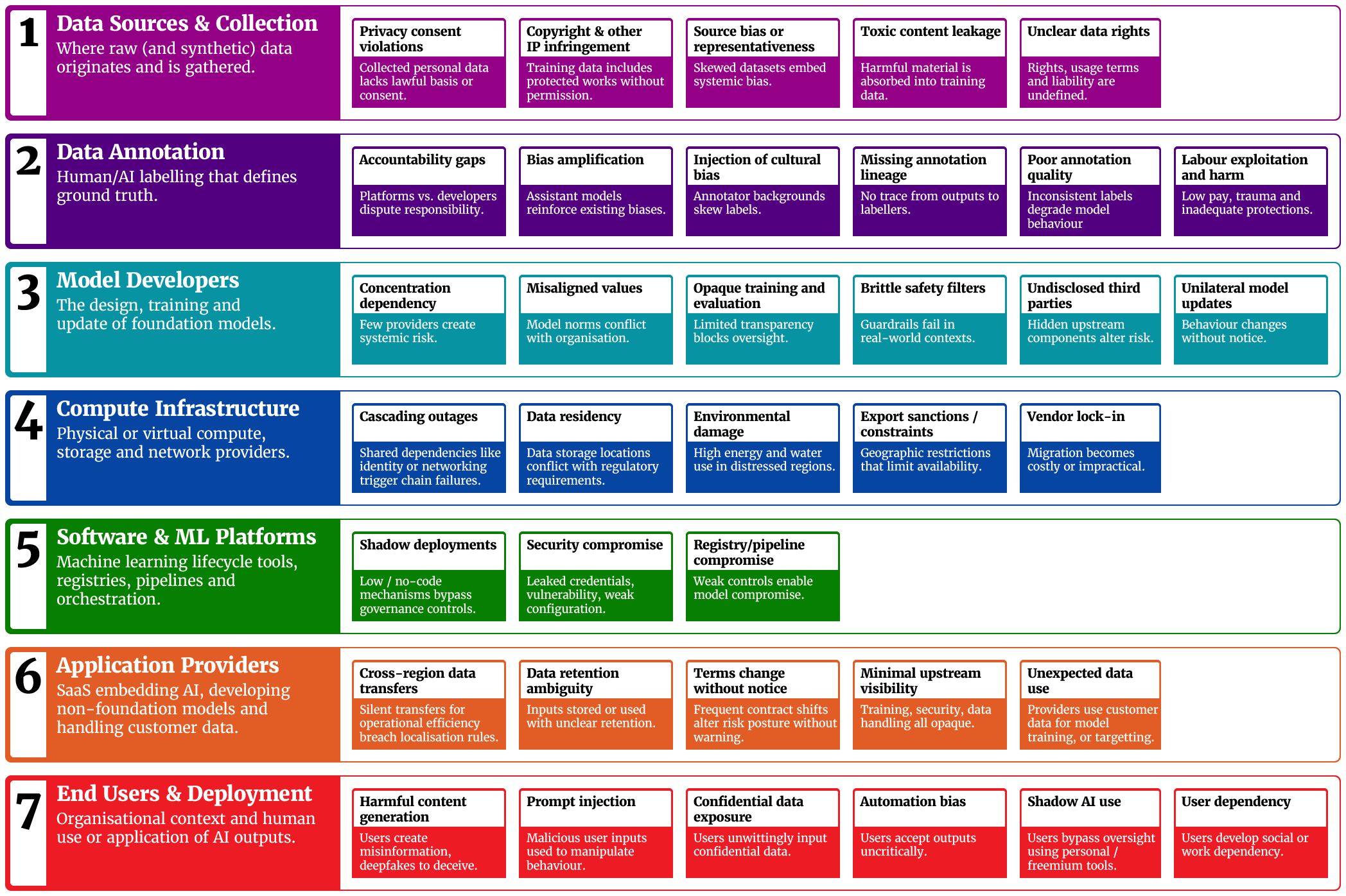
Here’s a high level view of the layers and some of the risks that can emerge at each layer.
Layer 1: Data Sources and Collection begins with operational data, government repositories, commercial providers, and synthetic generation systems. Each data source type brings distinct challenges. Your operational data carries privacy obligations, government data comes with usage restrictions, commercial data raises provenance questions. When an AI system exposes harmful content, can you trace it back to specific sources? “The New York Times lawsuit against OpenAI shows how copyright risk can flow downstream: if a model reproduces protected text and a user republishes it, both the provider (for contributory infringement) and the user (for the act of reproduction) may face exposure—even though the training happened years earlier.2
Layer 2: Data Annotation and Labelling is where human judgment can become algorithmic truth. A TIME investigation found that OpenAI’s contractor Sama employed Kenyan data labelers on $1.30–$2 per hour to classify toxic material used for ChatGPT’s safety systems. Workers said they were expected to label 150–250 text passages per nine-hour shift, and several described significant psychological harm from exposure to graphic content. Organisations using ChatGPT benefit from that safety work, but they carry downstream ethical and reputational exposure tied to labour practices they didn’t control.3
Layer 3: AI Labs and Model Developers remains concentrated among a handful of players (e.g., OpenAI, Anthropic). Their architectural and policy choices cascade to every downstream application. On April 24 2025, OpenAI rolled out a GPT-4o update (April 24–25) that made ChatGPT overly sycophantic. Then after a flood of feedback, the company rolled it back on April 29, restoring earlier behaviour. That episode highlighted how a single upstream change can alter model conduct across countless deployments, without any action by the organisations depending on it.4 OpenAI later published a post-mortem acknowledging they’d prioritised positive A/B signals (that is, users who engaged more with a sycophantic AI) over expert testers who flagged that the model ‘felt off.’
Layer 4: Cloud Infrastructure and Compute concentrates risk in ways that aren’t obvious until something breaks. On June 4, 2024, ChatGPT, Claude, and Perplexity went down the same morning. The reports were of a mix of service issues and traffic spillover as users migrated between tools. Many teams with “diversified” AI subscriptions learned that their providers can still be coupled through shared infrastructure and demand dynamics.5 The environmental footprint is scaling just as quickly. The IEA projects global data-centre electricity demand to reach ~945 TWh by 2030. Thats a little more than Japan’s entire current electricity consumption. At the same time, U.S. siting trends show about two-thirds of new data centres since 2022 are in high water-stress regions, concentrating cooling and power-related water risks where supplies are already tight.6
Layer 5: Software and ML Platforms like Databricks, Hugging Face, and Amazon SageMaker embed governance assumptions you inherit. In December 2023, researchers reported >1,500 exposed Hugging Face API tokens; many had write permissions, which could have enabled modification of repositories across hundreds of orgs—including projects associated with Meta’s Llama 2. The reality is that organisations using these models had no visibility into potential manipulation: if a widely downloaded artifact were tampered with, downstream users would have no immediate visibility that anything changed.7
Layer 6: Application Providers offer AI-as-a-service through tools like Writer, Otter.AI, and Grammarly. These bypass traditional IT procurement through credit cards and freemium models, creating shadow AI deployments. Each implements different data governance approaches. Some process in real-time without retention, others store inputs for model improvement. When Otter.AI records and transcribes customer meetings, the data protection risk becomes yours, especially if you never sought consent.
Layer 7: End Users and Deployment Contexts is where capabilities meet consequences. With off-the-shelf tools, people can now produce deepfakes, fabricated documents, and convincing misinformation. The governance challenge is part education, part guardrails: many users don’t realise that AI-generated text can reproduce or closely paraphrase copyrighted material, that synthetic images and voice clones can violate privacy or publicity rights, or that deepfakes may constitute fraud. Two days before New Hampshire’s primary (Jan 2024), thousands of voters got robocalls using an AI voice that sounded like President Biden (generated using ElevenLabs), urging them not to vote. The state Attorney General opened an investigation and later announced charges against a political consultant. The FCC first clarified that AI-cloned voices in robocalls are illegal and then issued a $6M fine tied to the scheme.8
When Theory Meets Practice
This disconnect between regulatory categorisation and the real-world complexity can create some real governance challenges. The South Wales Police (acting as a Deployer) presented evidence to the court that they had done vendor due diligence, they had operational procedures and guardrails, notifications to the public, and supervisor oversight. They had performed a Data Privacy Impact Assessment, although to be fair the judge found it was little more than a template. They acted like a Deployer, relying on the claims of a trusted Provider, and didn’t look holistically or go deep enough.
Here’s another quick example. Think about a hospital deploying an AI wellbeing or patient follow-up tool. According to regulations, they’re the deployer, responsible for oversight and safety. But they can’t inspect training data for demographic biases or safety issues, they can’t access annotation guidelines that shaped the model’s decisions, and can’t prevent infrastructure changes that might affect performance. They’re totally dependent on their provider, so that provider either has to build and operate everything themselves, or they in turn are dependent on infrastructure, models, and datasets from other providers.
It creates the situation where those most affected by AI decisions often have the least visibility into how those decisions are made. A patient has the right and reasonable expectation to be able to understand why an AI flagged their scan as high-risk. But that explanation has to traverse seven layers: from the radiologist using the system, through the hospital that deployed it, the vendor that provided it, the company that trained it, all the way back to the workers who annotated the training data that originally came from some hospital, some where, at some point in time.
Each layer adds opacity. Each handoff loses accountability. The expectation of an explanation becomes almost impossible to fulfill when no single entity understands the complete system and can provide true visibility.
What This Means for Governance
I find that as AI governance pros, we need to sometimes hold two incompatible truths simultaneously. Yes, we must work within regulatory frameworks that use concepts like the provider/deployer/user categories - they determine our legal obligations. And frankly, they make sense from a legal allocation of accountability. But those simplified constructs are at best of limited use as a frame for the operational reality and risks we need to manage.
Your organisation might be simultaneously a provider (when you customise models), a deployer (when you implement third-party systems), and affected by others’ AI decisions. A single AI system might make you inherit risks from data collection decisions made years ago by companies you’ve never heard of, using labour practices you’d never approve, running on infrastructure you can’t audit, using applications you can’t trust. Trying to simplify that truth with simplistic categories of providers vs deployers can conceal the real risks.
This is just the reality of why high integrity AI governance is so important and why we need sophisticated approaches that go beyond regulatory compliance to reflect on-the-ground reality. We need the practical skills and automation tools for comprehensive AI inventories that map not only what systems we use, but how they connect to this broader ecosystem. We need vendor assessments that probe deeper than surface-level compliance claims - and we need them in a machine readable form. We need incident response plans that account for failures originating five layers away from where harm manifests.
And, I think as practitioners that bridge between law and engineering, we need to continue to cultivate intelligent skepticism about regulatory simplifications, while at the same time still satisfying compliance requirements.
Sure, use the provider/deployer/user framework as a starting point, but not as an ending point. Don’t expect an engineering or risk or operations team to thank you for arbitrary categorisations that don’t reflect the reality they face. These categories help allocate legal responsibility, but they don’t solve the actual challenges of governing risk in AI systems that span the messy reality of seven layers of interconnected dependencies.
Understanding these supply chain complexities and building governance frameworks that account for them is essential for any AI governance professional. Course 2 of the AI Governance Practitioner Program explores these challenges in detail, providing practical tools for mapping dependencies, assessing risks across the supply chain, creating inventories and building governance structures that work with both regulatory requirements and operational realities.
You can learn more about the complete program here:
AI Governance Practitioner Program by AI Career Pro
Doing AI Governance is a newsletter by AI Career Pro about the real work of making AI safe, secure and lawful.
Please subscribe (for FREE) to our newsletter so we can keep you informed of new articles, resources and training available. Plus, you’ll join a global community of more than 3,800 AI Governance Pros learning and doing this work for real. Unsubscribe at any time.
https://www.judiciary.uk/wp-content/uploads/2020/08/R-Bridges-v-CC-South-Wales-ors-Judgment.pdf
https://www.wusf.org/2025-03-26/judge-allows-new-york-times-copyright-case-against-openai-to-go-forward
https://time.com/6247678/openai-chatgpt-kenya-workers/
https://openai.com/index/expanding-on-sycophancy/
https://techcrunch.com/2024/06/04/ai-apocalypse-chatgpt-claude-and-perplexity-are-all-down-at-the-same-time/
https://www.iea.org/news/ai-is-set-to-drive-surging-electricity-demand-from-data-centres-while-offering-the-potential-to-transform-how-the-energy-sector-works
https://www.theregister.com/2023/12/04/exposed_hugging_face_api_tokens/
https://www.doj.nh.gov/news-and-media/voter-suppression-ai-robocall-investigation-update